Beyond the Robot Voice: Achieving Natural and Expressive Text to Voice Narration
The technology for text-to-voice has advanced significantly. Recent developments in artificial intelligence and machine learning have opened the door to very lifelike and emotive synthetic speech, while early incarnations often generate robotic and monotonous voices. For companies, schools, and content producers alike, this has created many opportunities that enable them to harness the power of voice in fresh and captivating ways. However, how can we get beyond the artificial and produce text-to-voice narration that sounds natural? Let’s examine the main elements that have contributed to this fascinating development.
The Role of Advanced AI and Deep Learning
At its core are the complex algorithms that enable expressive text-to-speech. The subtleties of human language, such as intonation, stress, and rhythm, may now be captured by deep learning models that have been trained on enormous volumes of voice data. These algorithms can produce speech that represents the desired tone and style by analyzing material not just for its literal meaning but also for its emotional context. A genuine and captivating listening experience depends on the capacity to comprehend and mimic the nuances of human speech.
These AI models can also detect and adjust to various dialects and speaking styles. This implies that multiple voices with distinct personalities and characters may now be produced using text-to-voice engines. With this degree of personalization, authors may choose voices that best fit their material and intended audience, giving the narration an additional degree of realism.
Due to the continuous study and development in this area, even more remarkable outcomes are anticipated in the future. Text-to-voice technology will likely produce more subtle and human-like speech as AI models learn and develop, making it harder to distinguish between artificial and genuine voices.
Quick Guide to Text-to-Speech in CapCut
Forget robotic monologues! CapCut is a free video editing software. Its text-to-speech feature empowers you to infuse your videos with natural-sounding voices, effortlessly enhancing storytelling and dialogue. Here’s how to harness this powerful tool:
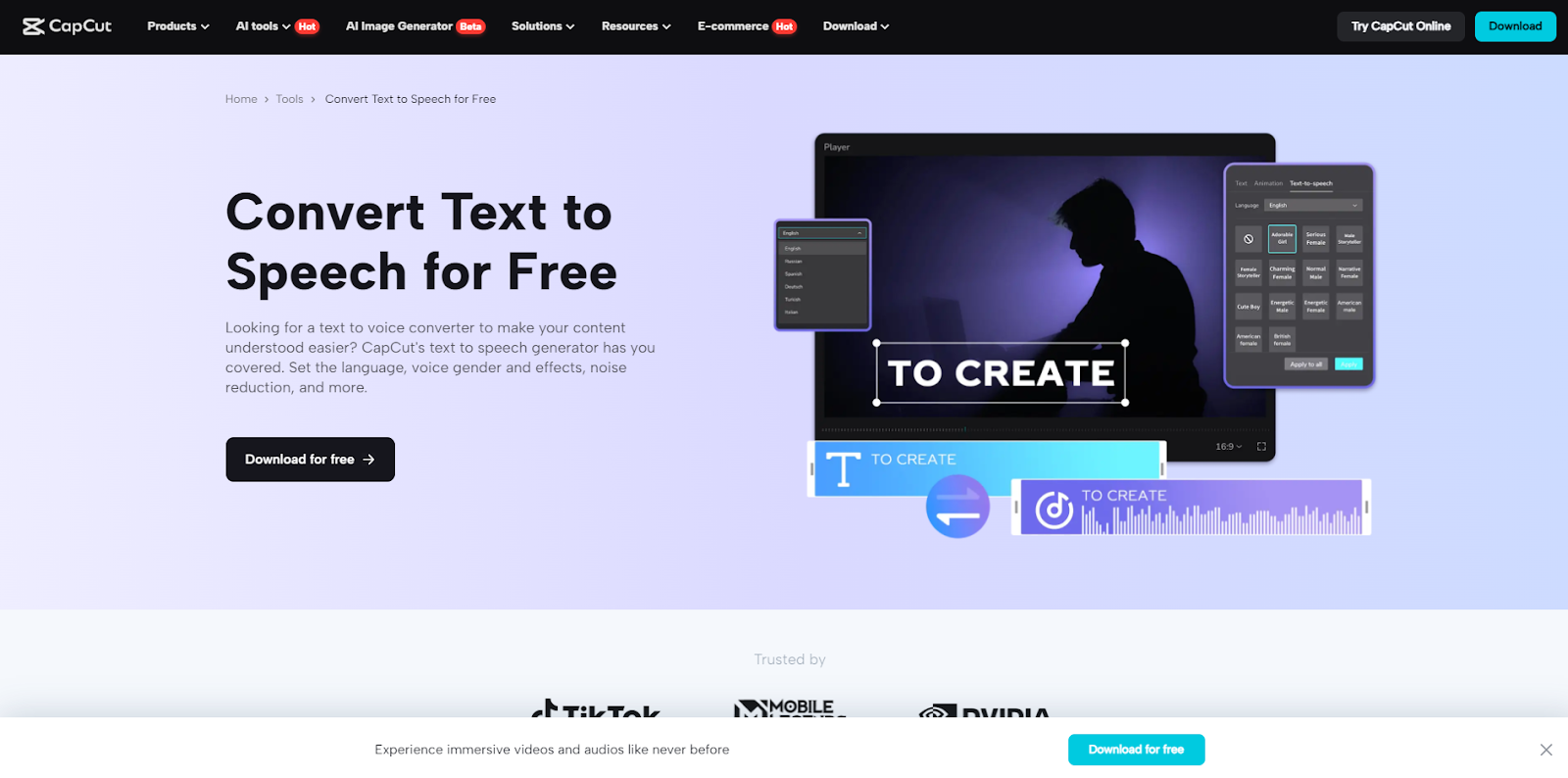
Step 1: From Text to Talk
Navigate to the timeline and tap the “Text” button. Select “Add Text” from the dropdown menu. Type or paste your desired text into the box. Finally, hit the “Text-to-Speech” button at the bottom of the text box – you’re now ready to convert text to voice!
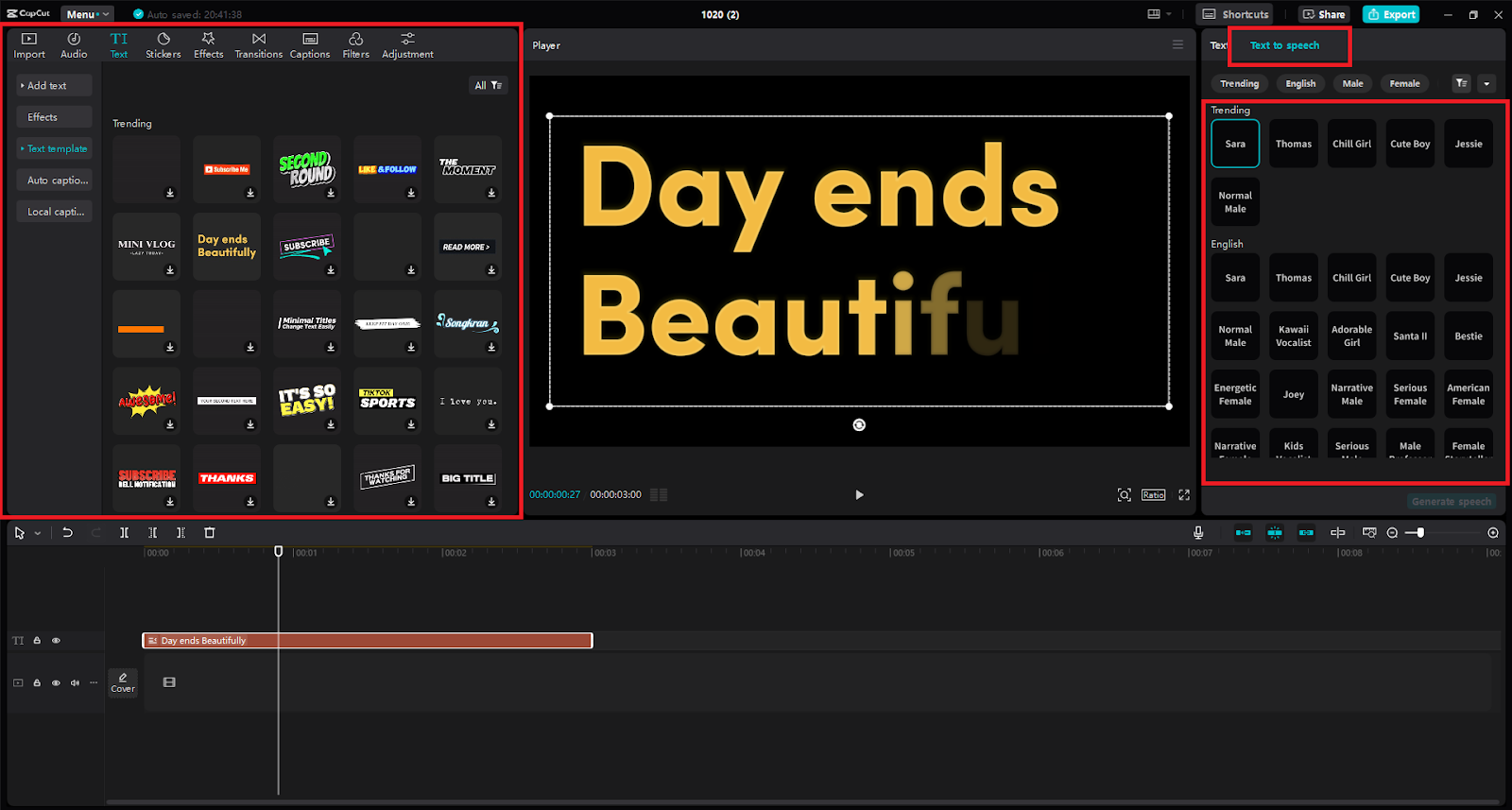
Step 2: Crafting Your Voice
This is where the magic happens. Choose your desired language and then explore the diverse range of voice styles, each with unique gender and accent options. While CapCut excels at adding text-to-speech, remember it also offers powerful tools to remove background from video, giving you even more creative control over your content.
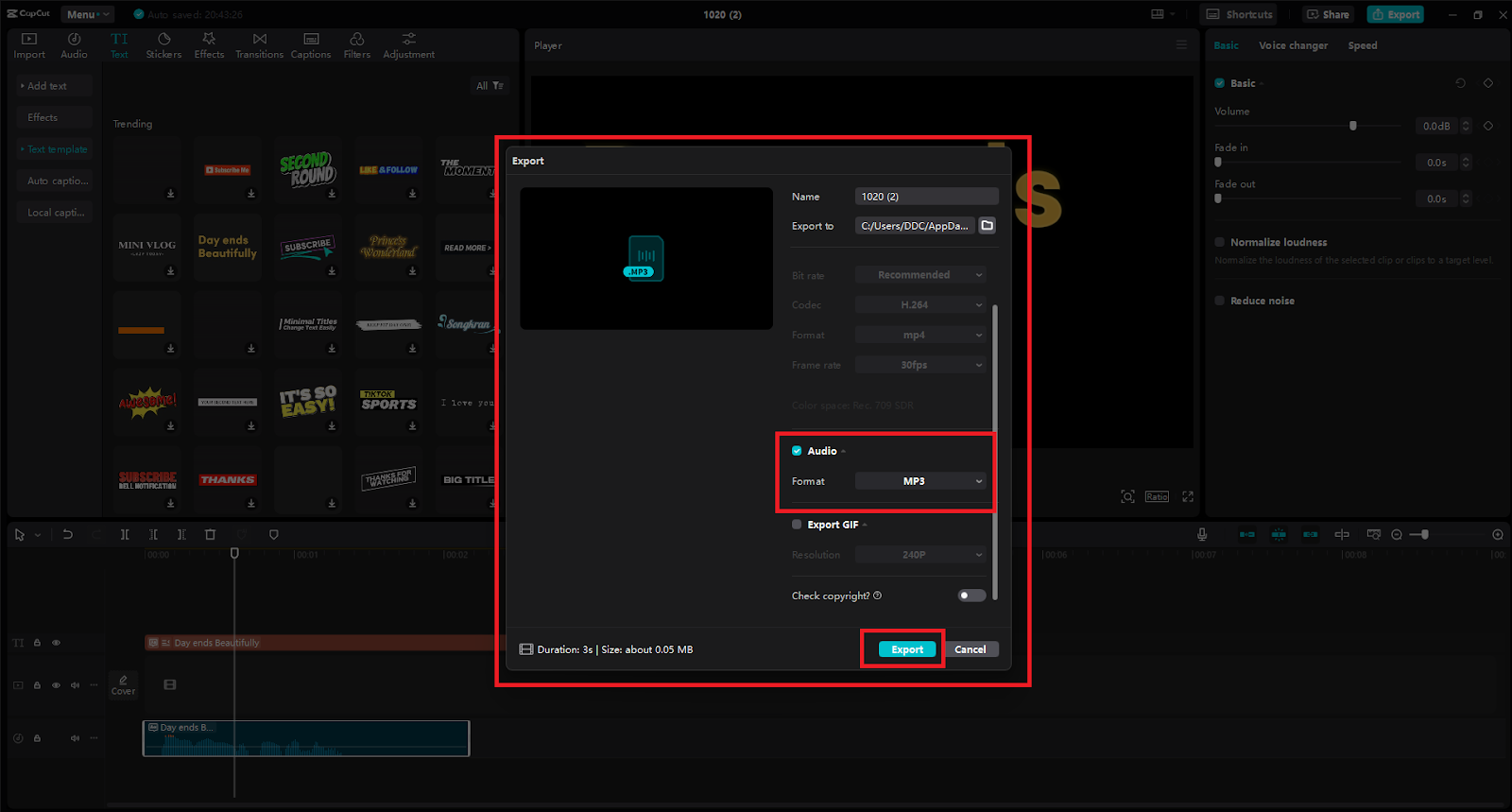
Step 3: Sharing Your Creation
Are you prepared to present your masterpiece? Select from various video formats and quality settings by clicking the “Export” button. To save your video with your freshly created speech included, click “Export” once again. You may download your work for offline reading or share it on social media.
Contextual Awareness and Natural Language Processing
Advanced text-to-voice engines use natural language processing (NLP) to comprehend the context of the text, going beyond just reading words aloud. Their speech becomes more accurate and natural-sounding due to their ability to recognize the connections between words, phrases, and sentences. NLP, for instance, assists the engine in distinguishing between the verb “present” and the noun “present,” guaranteeing proper intonation and pronunciation.
Understanding the text’s general subject and style is another aspect of contextual awareness. The AI can modify its delivery to fit the tone and style of the writing, whether it’s a dramatic story, a casual blog post, or a rigorous academic paper. This flexibility is essential for producing an engaging and genuine listening experience in various settings.
Text-to-voice engines may produce speech that is not only grammatically accurate but also semantically and emotionally rich by fusing natural language processing (NLP) with deep learning. As a result, the listener has a more engaging and immersive experience, which increases the material’s accessibility.
The Importance of High-Quality Voice Data
The naturalness of the output is greatly influenced by the caliber of the speech data utilized to train the AI models. Large and varied datasets with various voices and speaking styles are necessary for text-to-voice engines to be flexible and realistic. These datasets need to be meticulously selected and cleaned to guarantee that the AI learns from high-quality speech patterns.
The recordings should also include a variety of emotions and facial expressions to enable the AI to produce really expressive speech. This includes tiny characteristics like breaths and pauses as well as changes in pitch, tone, and tempo. By learning from this wealth of varied input, the AI may produce speech that is more realistic and human-like.
The continuous development of text-to-speech technology depends on collecting and processing high-quality voice data. As datasets grow in size and variety, future synthetic speech should become ever more expressive and lifelike.
Conclusion
Although AI models provide a solid basis, users may improve the produced speech’s expressiveness and naturalness via personalization and fine-tuning choices. This entails modifying elements like speaking tempo, pitch, loudness, and pauses to get a voice that precisely suits their requirements and tastes. Some sophisticated text-to-voice engines also allow users to adjust the intonation and emphasis of certain words or phrases, giving them even more control over the speech’s emotional effect. This degree of personalization guarantees a unique and captivating listening experience by enabling artists to adapt their voices to their particular content and audience.
Mircari Quotes And Sayings
 Examples of a Node Diagram
Examples of a Node Diagram
 Why app shielding is gaining popularity: Benefits and Importance
Why app shielding is gaining popularity: Benefits and Importance
 The Advantages of Satellite TV Packages
The Advantages of Satellite TV Packages
 How to Interpret and Use an Amortization Schedule?
How to Interpret and Use an Amortization Schedule?
 Shares viant myspace nasdaq 250m broadcastingcable
Shares viant myspace nasdaq 250m broadcastingcable
 Can You Add Pages to a PDF Without Deleting the Original Document?
Can You Add Pages to a PDF Without Deleting the Original Document?
 A Comprehensive Guide Of Healthcare SEO Agency For Healthcare Websites!
A Comprehensive Guide Of Healthcare SEO Agency For Healthcare Websites!
 Here’s How You Can Become A Data Engineer
Here’s How You Can Become A Data Engineer